
Gemini 3.1 Flash-Lite: Built for intelligence at scale
Quick Answer
Google DeepMind has launched Gemini 3.1 Flash-Lite, a cost-efficient AI model priced at $0.25/1M input tokens and $1.50/1M output tokens.
Quick Take
Google DeepMind has launched Gemini 3.1 Flash-Lite, a cost-efficient AI model priced at $0.25/1M input tokens and $1.50/1M output tokens. It delivers 2.5X faster performance than 2.5 Flash, achieving an Elo score of 1432 and excelling in tasks like translation and content moderation for high-volume workloads.
Key Points
- Gemini 3.1 Flash-Lite is available via Gemini API and Vertex AI.
- It outperforms 2.5 Flash with a 45% increase in output speed.
- The model is designed for high-frequency workflows and real-time experiences.
- Early adopters report efficiency and precision in handling complex tasks.
- Gemini 3.1 Flash-Lite is ideal for translation and content moderation.
📖 Reader Mode
~5 min readMar 03, 2026
Get best-in-class intelligence for your highest-volume workloads.
The Gemini Team
General summary
Gemini 3.1 Flash-Lite is now available in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI. Priced at $0.25/1M input tokens and $1.50/1M output tokens, it's cost-efficient and faster than 2.5 Flash. Use 3.1 Flash-Lite for tasks like translation content moderation generating user interfaces and creating simulations.
Summaries were generated by Google AI. Generative AI is experimental.
Basic explainer
Google made a new AI model called Gemini 3.1 Flash-Lite. It's super fast and cheap to use, so more people can use it. This AI is good at things like translating languages and checking content. Some companies are already using it to solve tough problems because it's both smart and efficient.
Summaries were generated by Google AI. Generative AI is experimental.

Your browser does not support the audio element.
Listen to article
This content is generated by Google AI. Generative AI is experimental
[[duration]] minutes
Today, we're introducing Gemini 3.1 Flash-Lite, our fastest and most cost-efficient Gemini 3 series model. Built for high-volume developer workloads at scale, 3.1 Flash-Lite delivers high quality for its price and model tier.
Starting today, 3.1 Flash-Lite is rolling out in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI.
Cost-efficiency without compromise
Priced at just $0.25/1M input tokens and $1.50/1M output tokens, 3.1 Flash-Lite delivers enhanced performance at a fraction of the cost of larger models. It outperforms 2.5 Flash with a 2.5X faster Time to First Answer Token and 45% increase in output speed, according to the Artificial Analysis benchmark while maintaining similar or better quality. This low latency is needed for high-frequency workflows, making it an ideal model for developers to build responsive, real-time experiences.

Gemini 3.1 Flash-Lite outperforms 2.5 Flash in speed and quality.
3.1 Flash-Lite achieves an impressive Elo score of 1432 on the Arena.ai Leaderboard and outperforms other models of similar tier across reasoning and multimodal understanding benchmarks, including 86.9% on GPQA Diamond and 76.8% on MMMU Pro–even surpassing larger Gemini models from prior generations like 2.5 Flash.
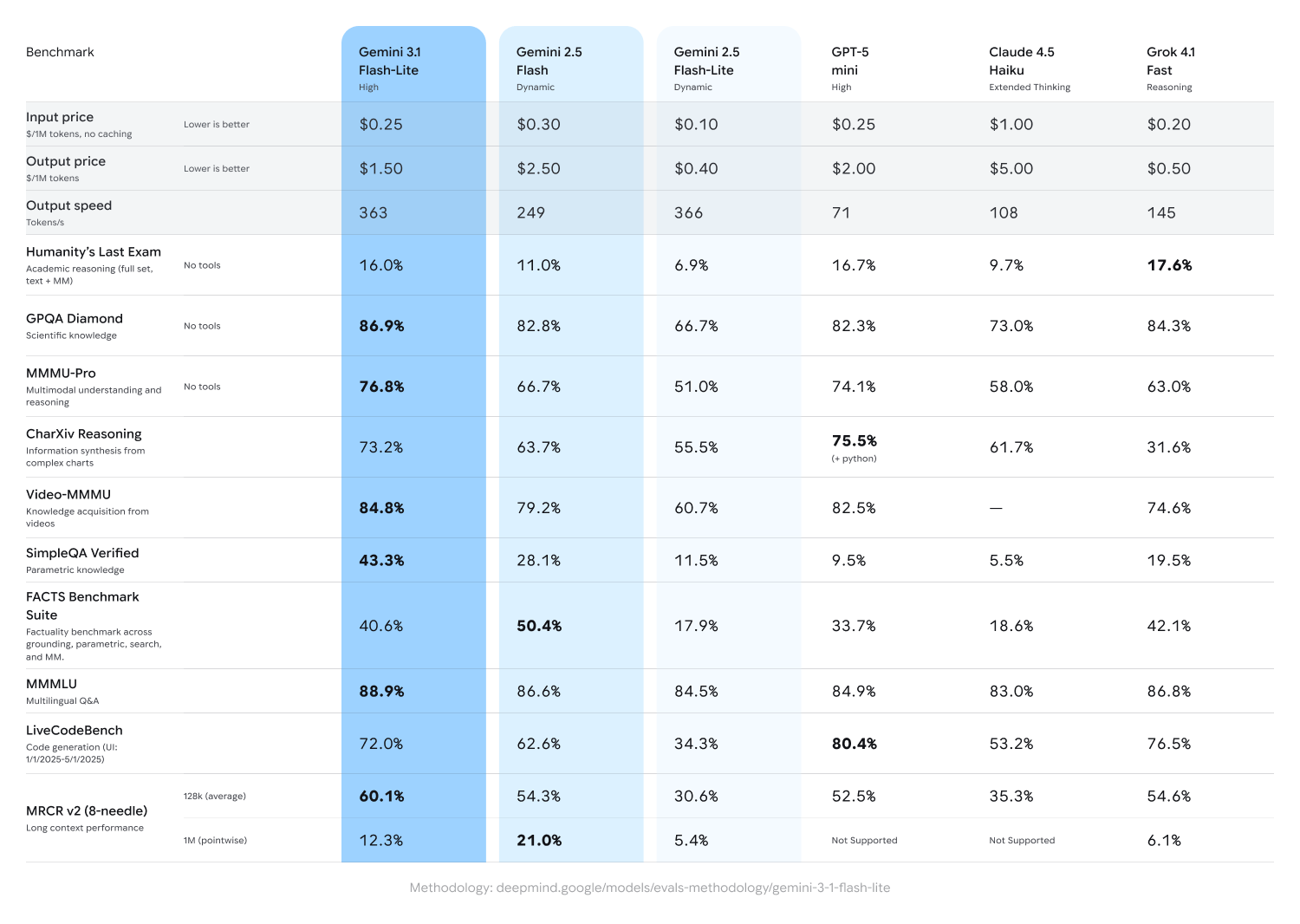
Adaptive intelligence at scale for developers
Beyond its raw performance, Gemini 3.1 Flash-Lite comes standard with thinking levels in AI Studio and Vertex AI, giving developers the control and flexibility to select how much the model “thinks” for a task, which is critical for managing high-frequency workloads. 3.1 Flash-Lite can tackle tasks at scale, like high-volume translation and content moderation, where cost is a priority. And it can also handle more complex workloads where more in-depth reasoning is needed, like generating user interfaces and dashboards, creating simulations or following instructions.
3.1 Flash-Lite can analyze and sort large numbers of content like images quickly.
Early-access developers on AI Studio and Vertex AI, and companies like Latitude, Cartwheel and Whering are already using 3.1 Flash-Lite to solve complex problems at scale. Early testers highlighted 3.1 Flash-Lite’s efficiency and reasoning capabilities, saying it can handle complex inputs with the precision of a larger-tier model, plus follow instructions and maintain adherence.




We look forward to seeing what you build with 3.1 Flash-Lite and the rest of the Gemini 3 series models.
Done. Just one step more.
Check your inbox to confirm your subscription.
You are already subscribed to our newsletter.
You can also subscribe with a
Related stories
.
— Originally published at deepmind.google
Want this in your inbox every morning?
Daily brief at your local 8am — bilingual EN/中文, free.
More from Google DeepMind
See more →
Introducing Gemma 4 12B: a unified, encoder-free
Google DeepMind has introduced Gemma 4 12B, a unified, encoder-free multimodal model designed to enhance performance across various tasks. This model aims to streamline processes in AI applications by eliminating the need for traditional encoders, potentially improving efficiency and reducing costs for developers and researchers in the field.

