Inside Target’s LLM-Based System for Semantic Matching in Marketing Forecast Pipelines
Quick Answer
Target has implemented a generative AI system for marketing campaign forecasting, achieving 75% coverage with top-ranked recommendations and 100% with the top three.
Quick Take
Target has implemented a generative AI system for marketing campaign forecasting, achieving 75% coverage with top-ranked recommendations and 100% with the top three. This system replaces manual rule-driven methods, utilizing embeddings and large language models to enhance decision-making and reduce operational overhead.
Key Points
- The new system uses embeddings and large language models for improved campaign similarity matching.
- Coverage increased from 75% to 100% when considering the top three historical matches.
- Manual rule maintenance was reduced, improving efficiency in forecasting workflows.
- A feedback mechanism refines embeddings based on performance data from completed campaigns.
- The architecture separates embedding generation, retrieval, and ranking for better observability.
📖 Reader Mode
~3 min readTarget has developed a generative AI-based system to improve marketing campaign forecasting by surfacing and ranking similar historical campaigns before a new campaign is launched. The system is used internally by marketing and analytics teams at Target to support planning decisions across campaign types and channels. It is designed to reduce manual effort in identifying comparable campaigns, improve consistency in forecasting, and scale decision-making as campaign diversity increases.
To evaluate the system, Target used a time-separated train-test methodology across a diverse set of recent marketing campaigns. According to the company, the model achieved 75% coverage when only the top-ranked recommendation was considered. When the recommendation depth was expanded to the top three matches, coverage increased to 100 percent, meaning every evaluated campaign had at least one suitable historical match. Target stated that this improvement reduced the need for manual search and correction when identifying comparable campaigns for forecasting workflows.

Coverage by Recommendation Depth (K) (Source: Target Blog Post)
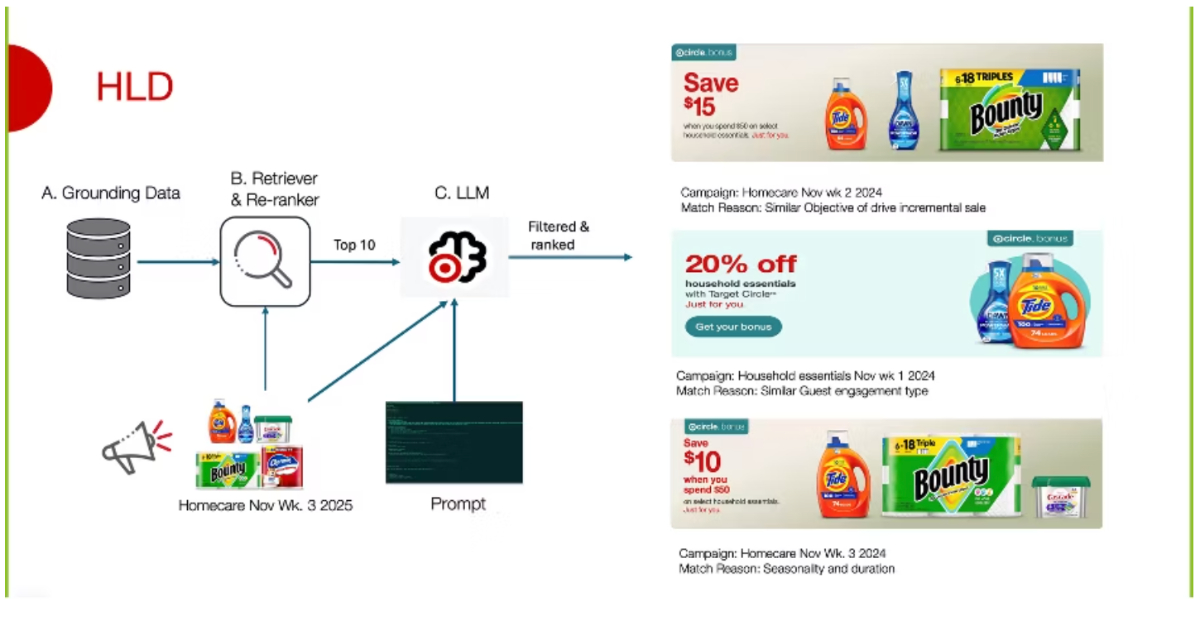
This new system replaced earlier rule-driven logic and simpler similarity matching techniques. The prior system required ongoing manual rule maintenance and struggled to generalize to evolving campaign formats as channel volume and complexity increased, leading to operational overhead and reduced effectiveness for newer campaign types. The new system uses a retrieval-augmented architecture combining embeddings and large language models. Historical campaign data is normalized and converted into embeddings that capture semantic meaning from structured attributes such as audience segment, product category, channel, and campaign intent. These embeddings are stored in an internal index for similarity search.
When a new campaign is created, the system generates an embedding from its metadata and retrieves candidate historical campaigns with similar characteristics. These candidates are passed to a large language model for ranking and refinement. The model evaluates similarity using structured constraints and contextual signals, returning a ranked list of relevant campaigns with explanations for each match.
The architecture follows a multi-stage pipeline separating embedding generation, retrieval, and large language model-based ranking. This separation enables independent tuning and improves observability of intermediate outputs. Marketing analysts review retrieved candidates and model-generated explanations before using them in forecasting workflows, ensuring human validation remains part of the process.

High-level design of new system (Source: Target Blog Post)
Rather than directly predicting campaign outcomes, the system supports decision-making by identifying historically similar campaigns that inform expectations. This shifts forecasting from rule-based systems to a retrieval and reasoning-based workflow, improving interpretability by grounding recommendations in historical attributes.
Target Engineering noted that a key challenge with the previous system was the operational burden of maintaining rule sets as campaign patterns evolved. The new approach reduces dependency on manual rule updates by using semantic similarity and model-driven ranking to generalize across campaign variations. It also improves coverage for long tail campaign types that previously lacked reliable rule definitions.
The system includes a feedback mechanism that uses performance data from completed campaigns to refine embeddings and improve retrieval quality over time. According to Target Engineering, this allows the system to evolve with new campaign outcomes and improves the relevance of retrieved historical matches in future forecasting workflows.
About the Author
Leela Kumili
Show moreShow less
— Originally published at infoq.com
Want this in your inbox every morning?
Daily brief at your local 8am — bilingual EN/中文, free.
More from InfoQ AI, ML & Data Engineering
See more →
Google OpenRL is an Experimental Self-hosted API for LLM Post-Training Fine-tuning
Google's GKE Labs has launched OpenRL, an open-source self-hosted API designed for fine-tuning Large Language Models (LLMs) on Kubernetes clusters. This initiative aims to streamline post-training processes, making it easier for developers to enhance LLM performance without relying on external services.

