StepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension
Quick Take
StepFun launched StepAudio 2.5 Realtime, a customizable real-time speech model excelling in benchmarks.
Key Points
- Supports real-time speech in Chinese and English.
- Achieved top scores in five benchmark dimensions.
- Features roleplay-specific RLHF and paralinguistic comprehension.
Article Excerpt
From source RSS / original summaryStepFun, the Shanghai-based AI lab, released StepAudio 2. 5 Realtime in May 2026 — an end-to-end real-time speech large language model with fully customizable persona capabilities. The model connects via a WebSocket API, supports Chinese and English, and ranked first across all five benchmark dimensions tested in April 2026, including an 80. 41 human evaluation score and 82. 18 on paralinguistic comprehension. The post StepFun Releases StepAudio 2.
5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension appeared first on MarkTechPost.
Reader Mode unavailable (could not extract clean content).
Want this in your inbox every morning?
Daily brief at your local 8am — bilingual EN/中文, free.
More from MarkTechPost
See more →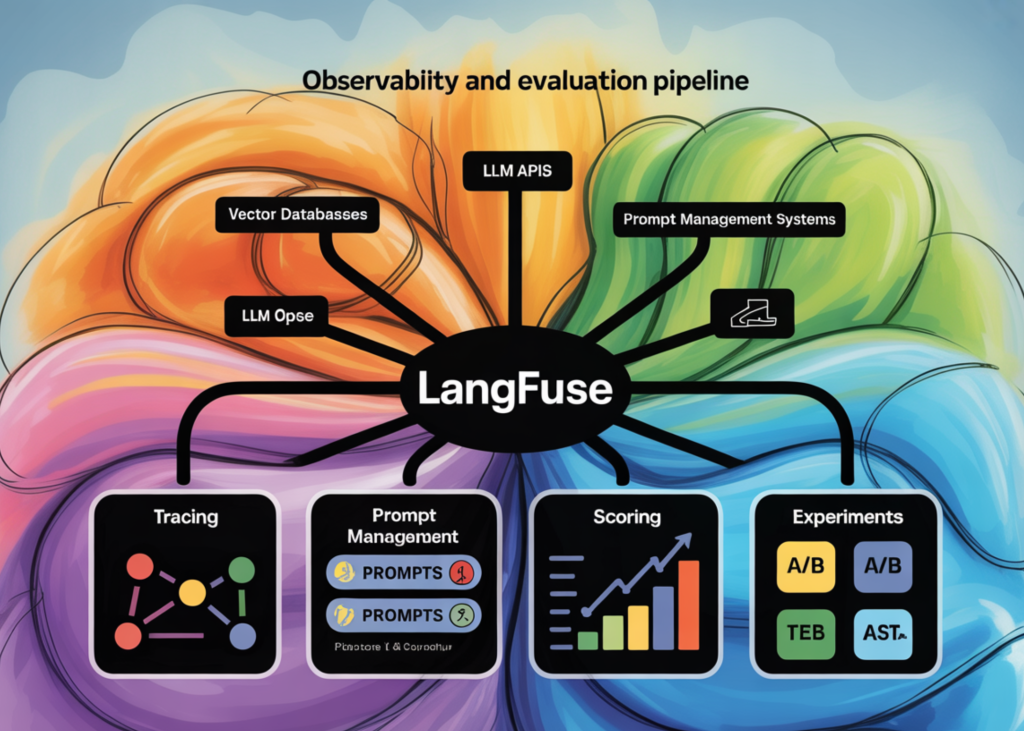
Build a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and Experiments
This tutorial guides building a Langfuse pipeline for observability and evaluation without paid model access.
